硬件系统
计算机的硬件主要分为五部分:运算器、控制器、寄存器、输入设备、输出设备。其中运算器和控制器总称为中央处理器(CPU),指的是计算机中对信息进行告诉运算处理的主要部件。
存储器则使用来存储程序、数据和文件,一般是由快速的内部存储去(容量可达数百兆字节,甚至数G字节)和慢速的外部存储区(容量可达数十G或数百G以上)组成,比如计算机中的内存条和固态硬件属于存储器。
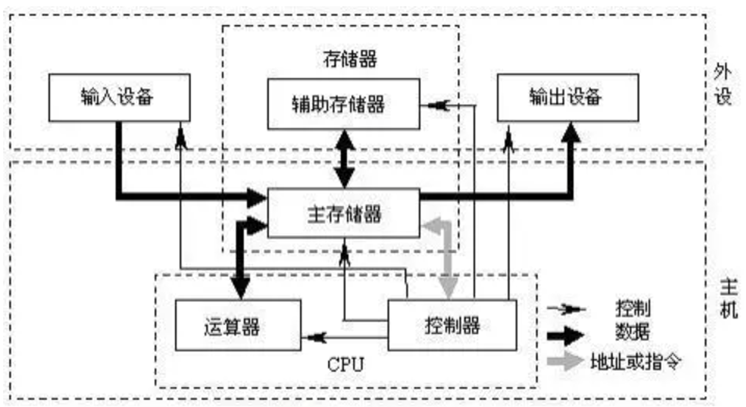
输入设备与输出设备就是用于实现人机交互的信息转换器,由计算机的输入输出控制系统负责管理外部设备与主存储器之间的信息交换,常用的输入设备主要由键盘以及鼠标,输出设备则是显示器、打印机以及其他可连接到计算机上的I/O设备。
软件系统
如果计算机只有硬件系统,那么计算机是无法正常工作的,因为计算机是由基本的电子元件组成的,而电子元件的状态是需要由软件控制的,所以计算机必须要搭载软件系统,计算机的软件系统与硬件系统是相互依赖的。
计算机的软件系统一般由两部分组成:系统软件和应用软件。系统软件指的是计算机中的操作系统以及硬件驱动程序等,应用软件指的是用户可以使用的各种程序设计语言以及利用程序设计语言设计的应用程序的集合。
文件系统
计算机的系统软件和应用软件其实都是大量的程序和数据组成的,也就说两者都需要存储在计算机的存储器中,这些程序和数据以什么样的格式存储到存储器中就由文件系统决定。
可以把文件系统理解为是一种“标准”或者“格式”,只要遵循这套标准就可以正确的访问存储在磁盘中的数据。
标准的指定则是至关重要,但是由于技术原因或者商业利益考虑,导致现在文件系统没有办法统一。所以目前存在多种文件系统,常见的由FAT32、NTFS、EXT4…..,我们电脑的磁盘文件系统就是NTFS格式。
当发现磁盘出现某些扇区损坏导致数据丢失时,就可以对磁盘进行格式化,在格式化磁盘的时候就可以指定文件系统类型。
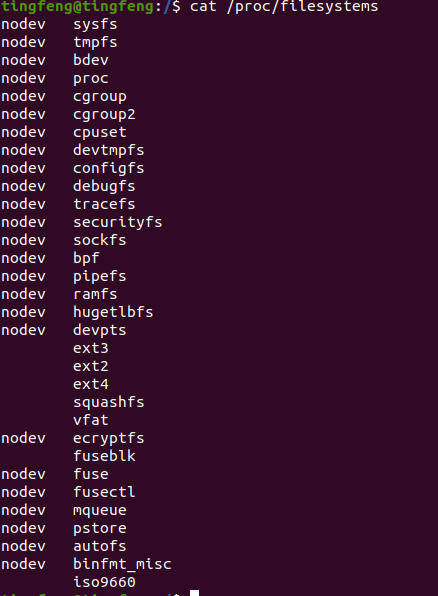
Linux系统也支持多种文件系统类型,可以在linux系统根目录的/proc目录下查阅filesystems
计算机中搭载的Linux操作系统就属于系统软件,操作系统的作用是用来连接应用软件和底层硬件,因为涉及到Linux内核的安全管理机制,所以用户空间是没有办法直接访问硬件设备的。
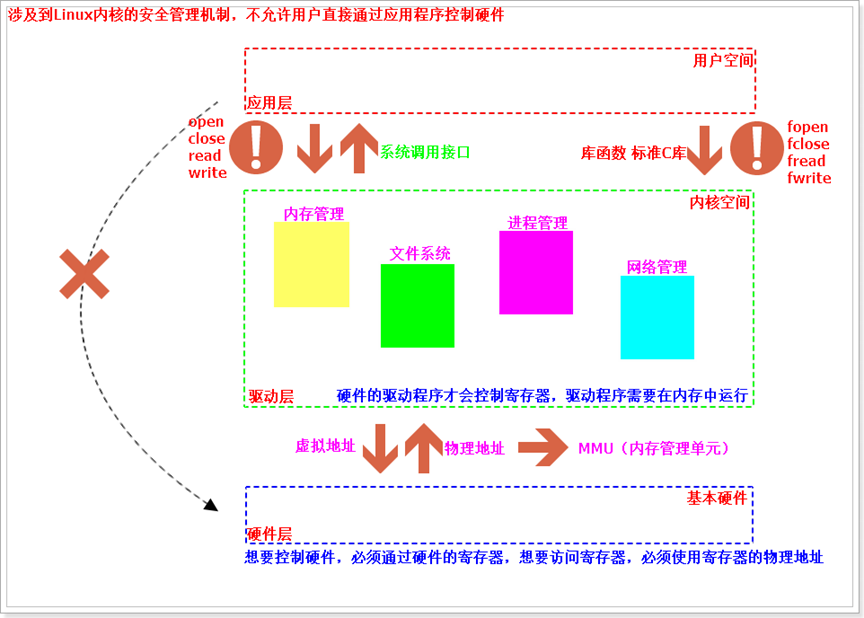
用户必须要通过Linux内核提供的相关函数接口才能实现对硬件的控制,这样用户也不需要关心硬件应该如何控制,只需要把参数提交给内核,然后由内核把控制参数传递给硬件设备,从而让内核控制硬件设备完成相关动作。
因此,用户需要先利用程序设计语言设计出源文件,然后操作系统内核需要从磁盘中访问源文件,再通过编译器把源文件编译生成可执行文件,最后内核再访问存储磁盘中的可执行文件,从而把控制硬件的参数读取出来。
所以访问磁盘中的文件也是操作系统要做的工作之一。操作系和文件系统可以理解为一种“合作”关系,文件系统指定了读写文件的标准,而操作系统会按照这套标准去完成访问文件的动作。
Linux系统的目录
1.根文件系统
注:Linux系统是离不开文件系统的,在Linux内核启动之后首先搭载的就是根文件系统rootfs,根文件系统rootfs本质就是文件系统,只不过是Linux内核挂载的第一个文件系统。而Linux内核源码是存储再文件系统中,所以在Linux系统启动的过程中启动引导城西uboot会加载内核并利用内核挂载根文件系统。

跟文件系统被挂载之后,一些服务程序和一些脚本文件才看可以存储在文件系统中,其他的文件系统才可以被挂载。
根文件系统会提供一些服务:比图根文件系统会提供一个根目录(存储文件和目录)、提供一个shell终端(用户才可以输入命令)、根文件系统会存储应用程序。总而言之,Linux内核离开根文件系统是无法正常工作的。
Linux系统的所有程序和数据都是以“文件”的形式的存储在文件系统中,所有Linux用户和程序看到的文件、目录、软连接以及文件保护信息都存储在其中。这种机制有利于用户和操作系统的交互,这也是Linux系统“一切皆文件”的原因。
2.目录的结构分析
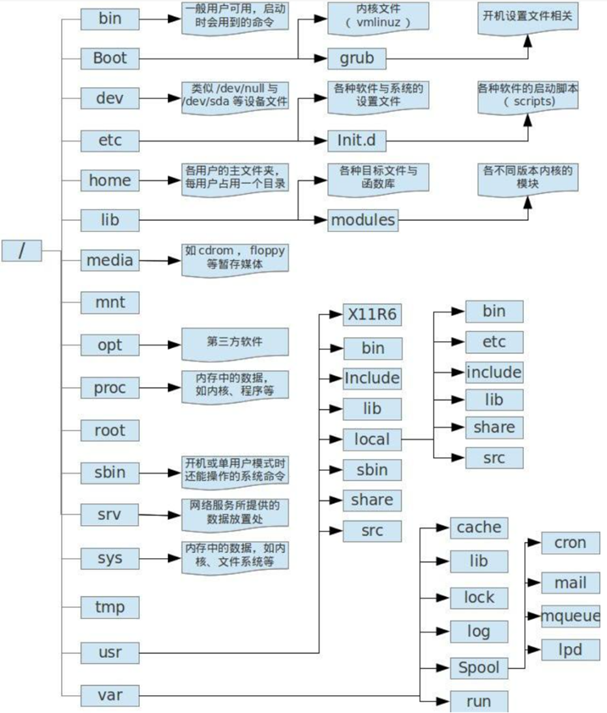
在Linux操作系统中,所有的文件和目录都被组织成以根节点“/”开始的倒置的树状结构
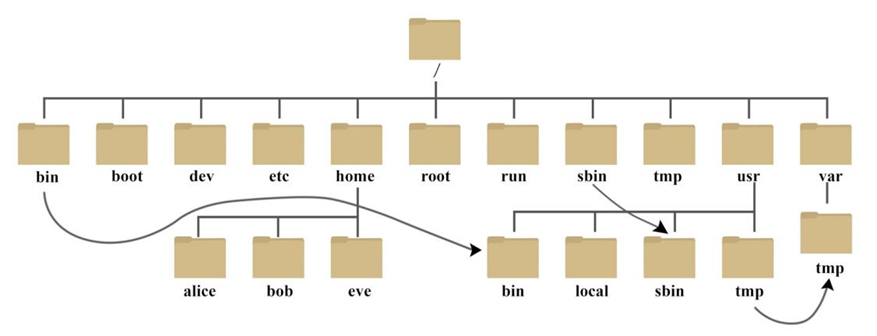
文件系统的最顶层是由根目录开始的,系统使用“/”来表示根目录,在根目录之下的既可以是目录(相当于windows中的文件夹),也可以是文件,而每一个目录中又可以包含子目录或文件,如此反复就可以构成一个庞大的文件系统。
使用这种树状、具有层次的文件结构主要目的是方便文件系统的管理和维护,为了方便查看Linux系统的目录结构,使用tree命令可以以树状结构打印出目录的层次
安装tree命令:
在shell终端中输入命令:sudo apt-get install tree
3.Linux的文件类型
由于程序和数据在Linux系统中都是以文件的形式存在,不同格式的数据所对应的文件类型也各不相同,在Linux系统下可以把文件的类型分为七种:
1.规则文件/普通文件(-):存在于外部存储中,用于管理普通数据
2.目录文件(d):用于存放目录项,是文件系统管理的重要文件类型。
3.链接文件(l):用于简介访问另外一个目标文件,相当于windows快捷方式
4.管道文件(p):一种用于进程间通信的特殊文件,也被称为管道FIFO
5.套接字文件(s):一种用于网络间通信的特殊文件
6.字符设备文件(c):字符设备在应用层 的访问接口
7.块设备文件(b):块设备在应用层的访问接口
4.文件操作接口说明
以上提到的数据都是以文件的形式存储在Linux系统中,并且Linux系统为了简化不同类型文件的操作流程,在设计访问接口时也遵循POSIX标准,而POSIX标准就是对不同操作系统的访问接口做出统一的规范,目的时提高程序的兼容性和可移植性。C语言同样有语法标准,并且C语言标准在发布的时候也会发布对应的库函数提供给用户。这些库函数也同样遵循POSIX标准进行设计,而遵循POSIX标准设计出来的函数的集合也被称为标准库,如标准C库中提供了标准的输入输出函数,这些函数在Linux系统可以使用,同样在windows系统中使用。用户可以根据标准输入输出头文件<stdio.h>中的函数声明进行调用,Linux系统下该头文件路径为/user/include

由于任何一种操作系统都会由访问磁盘文件的需求,所以POSIX标准中同样对访问文件的输入输出接口做出了约束,这些访问文件的函数接口在C原因呢标准中都有具体的描述。
标准C库中关于文件输入输出的函数接口一般被称为标准IO,访问文件常用的标准IO函数有fopen()、fread()、fwrite()、fclose()、fgetc()、fputc()、fgets()、fputs()、fprintf()、fscanf()等。
C语言标准
注:打开文件的目的无非就是对文件进行读写操作,所以每次当程序运行的时候已经由三个文件流被打开,分别是标准输入stdin、标准输出stdout、标准出错stderr,这三者在stdio.h中也是FILE指针
按行读取

标准库中提供了一个fgets函数,通过C99标准可以知道该函数的作用是从文件指针stream指向的文件中读取一行字符,并把读取的字符存储在指针s所指向的字符串内,当读取到n-1个字符、或者已经读取到文件末尾(EOF)、或者读取到换行符’\n’时,则函数调用停止。
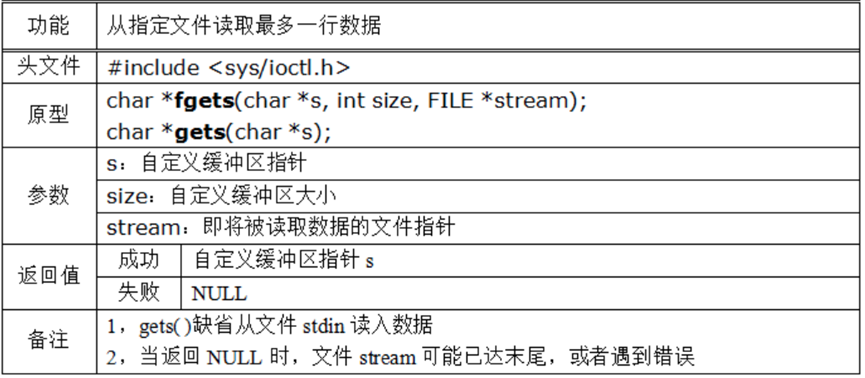
为什么fgets函数读取到换行符\n时会结束?fgets函数中的参数n的意义是什么??
用户调用fopen打开文件之后,可以把数据写入到文件中以及从文件中读取数据,但是实现读取和写入的过程中其实内核并没有直接操作文件,而是在操作指向文件的结构体指针FILE,也就是用户写入的数据和读取的数据会先存储在FILE结构体的缓冲区中,当用户调用刷新缓冲区的函数或者其他读写函数时,FILE结构体的缓冲区会被刷新,数据才会被系统写入文件。
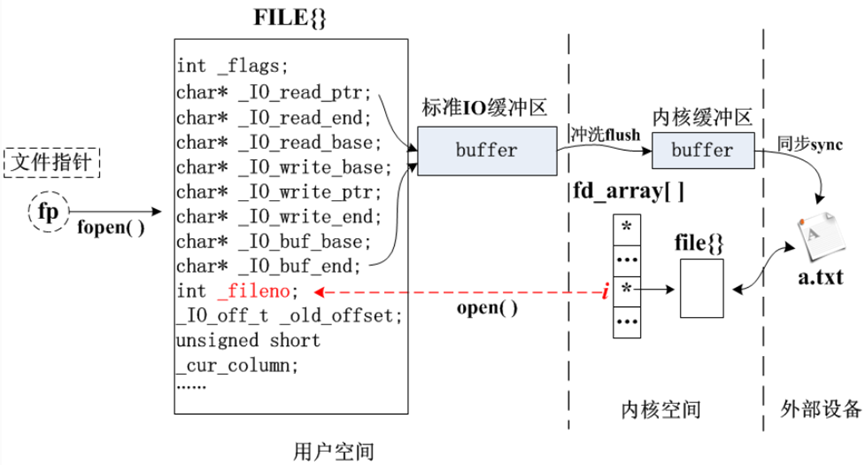
可以看到,每当使用标准IO的读操作函数,试图将数据从文件 a.txt读取出来时,数据都会流过标准输入缓冲区,然后再在适当的时刻冲洗(或称刷新,flush)到内核缓冲区,最后才真正得到数据。
缓冲区的出现其实就是由于输入设备和输出设备对于数据的读写速度比较慢,其实就是CPU为了降低输入输出次数,目的是为了提高运行效率,避免长时间的等待,所以内核就在内存中提供了一块空间作为缓冲区,缓冲区也可以称为缓存(Cache),是属于内存空间的一部分。
根据IO设备的不同,可以把缓冲区分为输入缓冲区和输出缓冲区,同样,根据刷新形式的不同,可以把缓冲区分为三种:全缓冲、行缓冲、无缓冲。
全缓冲:指的是当缓冲区被填满就立即把数据冲刷到文件、或者在关闭文件、读取文件内容以及修改缓冲区类型时也会立即把数据冲刷到文件,一般读写文件的时候会采用
无缓冲:指的是没有缓冲区,直接输出,一般linux系统的标准出错stderr就是采用无缓冲,这样可以把错误信息直接输出。
行缓冲:指的是当缓冲区被填满(一般缓冲区为4KB,就是4096字节)或者缓冲区中遇到换行符’\n’时,或者在关闭文件、读取文件内容以及修改缓冲区类型时也会立即把数据冲刷到文件中,一般操作IO设备时会采用,比如printf函数就是采用行缓冲。
当然,全缓冲和行缓冲除了以上几种情况外,当程序结束时缓冲区也会被刷新,另外,也可以采用函数库中的fflush函数手动刷新缓冲区。

注:对于标准输出stdout而言默认时采用行缓冲的,而对于标准出错stderr而言默认是采用无缓冲的,对于普通文件而言默认是采用全缓冲的。

发表回复